WebMCP Explained: AI Agents Are Changing the Web
Table of Contents
In March 2026, Cloudflare CEO Matthew Prince said at SXSW that bot traffic could exceed human traffic by 2027. The underlying logic is easy to follow: a person opens a few tabs. An agent can issue hundreds or thousands of requests for the same task in parallel, compare sources, and prepare actions.
For many operators, bots used to be primarily a security problem: scrapers, spam, and DDoS attacks . With browser agents and AI workflows, a second category is now emerging: bots that are not trying to break things, but to read, evaluate, and act on your behalf.
That is exactly where WebMCP becomes interesting. Not as a finished new web standard, but as an early concept for how websites and browser-based agents could interact in a more structured way.
What is WebMCP?
WebMCP is an early approach that allows websites to expose explicit capabilities and context to an agent in the browser. Instead of forcing an agent to guess its way through HTML and painfully interpret buttons or forms via DOM scraping, a website can describe available actions more clearly.
The core idea is straightforward:
- A website exposes structured capabilities instead of just a visual interface.
- An agent can use those capabilities more precisely within the browser context.
- The user stays in the flow of the tab instead of clicking through every step manually.
The important qualification is this: as of April 2026, WebMCP is not a ratified W3C standard and not a broadly available browser feature. It is an early draft or preview direction that Chrome is publicly discussing and experimenting with.
What is the difference between MCP and WebMCP?
This is where a lot of discussions become sloppy. WebMCP is not simply “MCP for websites”, nor is it the direct successor to MCP.
- MCP describes, in general terms, how models and clients can talk to tools, data sources, and services.
- WebMCP addresses the specific case where an agent interacts with a website inside the browser.
- MCP and WebMCP therefore solve related, but different, problems.
That distinction matters. Otherwise, it becomes easy to get the impression that the entire open web is about to move wholesale to a single new standard. We are not there.
Why could bot traffic rise sharply by 2027?
The key point is the fan-out effect Prince described. If you are shopping for a laptop today, you might open 5 to 10 pages. An agent can split the same task into parallel work:
- It checks multiple retailers at once.
- It compares shipping times, pricing, return policies, and warranty details.
- It filters out duplicates, ads, and irrelevant results.
- It hands back a condensed decision brief instead of raw browsing noise.
The exact number of requests depends on the task. But the direction is clear: agents multiply the number of lookups per user because they work in parallel and automate more intermediate steps than a human ever would.
My personal shift: from searching to delegating
I can already feel that shift in my own workflow. Research used to mean typing a search query, opening three to ten tabs, throwing away content junk, refining the query, and starting over. Today, I delegate a lot of that work.
One concrete example from my day-to-day workflow: when I track new hardware, security updates, or changes in tools, I do not just run one-off searches. I have agents check, filter, and prioritize those topics repeatedly. Critical hits go straight to my phone as push alerts. Less urgent items land in a dashboard or a reading queue for later.
The difference is not just convenience. The difference is that setups like this generate traffic continuously, even when I am not actively browsing. That alone makes it easier to understand why bot traffic can grow much faster, statistically, than human sessions.
What does that mean for websites and SEO?
I do not think classic SEO is “dead”. But I do think it is very likely to be supplemented. It is no longer enough for search engines to understand your content. Increasingly, agents will also need to extract, compare, and incorporate it into their own context.
For that next layer, four things matter most:
- Clean structure: headings, tables, forms, and semantic HTML need to be unambiguous.
- Machine-readable data: Schema.org, consistent metadata, and clearly named fields help more than flowery marketing copy.
- Accessible flows: if key information or actions are hidden behind brittle JavaScript constructs, agents are slowed down unnecessarily.
- Latency and reliability: the sites that respond quickly, consistently, and predictably will have a technical advantage.
You will hear the term AEO (Agent Engine Optimization) more often in this context. I would not treat it as a replacement for SEO, but as an additional visibility discipline for agentic systems.
What operators should do now
If you run a website, portal, or application today, I would not start with hype. I would start with hygiene:
- Expand structured data. Review where
Schema.orgalready makes sense: articles, products, FAQs, organization data, breadcrumbs. - Make important content reachable without unnecessary friction. Pricing, availability, specifications, contact paths, and core functionality should not be buried behind fragile UI tricks.
- Simplify forms and interaction flows. Clear labels, stable buttons, predictable states, and clean HTML help both humans and agents.
- Measure performance rigorously. Slow response times, unnecessary redirects, and unstable frontends reduce both visibility and usability.
- Separate bot traffic properly. Not every bot is malicious, but not every bot is valuable either. Monitoring, rate limits, and clear policies matter more going forward.
- Offer structured access where it makes business sense. That might mean an API, a feed, clean metadata, or eventually a more agent-friendly browser flow.
Who pays for the internet if agents do the clicking?
The economic question is at least as interesting as the technical one. Alphabet reported $82.3 billion in advertising revenue for Q4 2025, while Meta reported roughly $58.1 billion in the same period. Those numbers illustrate one thing very clearly: today’s web is still deeply tied to attention, clicks, and ad inventory.
If users increasingly consume answers through agents instead of visiting pages themselves, that puts the current model under pressure. That does not automatically mean advertising disappears. But it does suggest that direct access, data licensing, APIs, and subscription-style models could become more important.
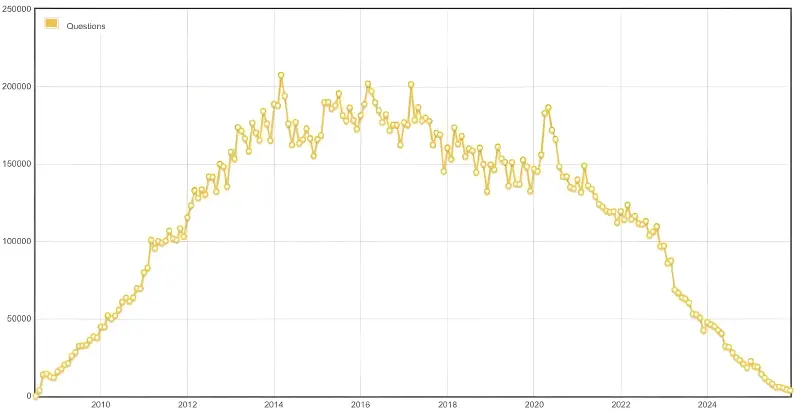
One interesting signal here is Stack Overflow. The volume of new questions has been under visible pressure since the AI boom, while the company has positioned its knowledge base and data licensing more aggressively as a product. That does not prove a universal new model yet, but it does point in a direction: value may increasingly come not only from pageviews, but from licensed, structured access to knowledge.
FAQ
Is WebMCP already an official web standard?
Is WebMCP the same thing as MCP?
Does this mean SEO is over?
Do websites need to be rebuilt for AI agents right now?
Why does bot traffic increase so much when agents are involved?
Conclusion
If you run a website today, there is no need to panic and rebuild everything around WebMCP tomorrow. But you should start checking now whether your content is structured, fast, machine-readable, and cleanly accessible.
That is what will determine whether you merely look good in an agentic future, or whether your site is actually usable by the systems that matter.
Cheers, Joe
Sources and further reading
- TechCrunch: Cloudflare CEO says online bot traffic will exceed human traffic by 2027
- Chrome for Developers: WebMCP Early Preview Program
- Chrome for Developers: When to use WebMCP and MCP
- WebMCP Draft
- Alphabet: Q4 2025 Earnings Release
- Meta: Q4 2025 Results
- Stack Overflow Data Licensing
- Prosus HY2026 Summary Consolidated Financial Statements