WebMCP समझाया गया: AI एजेंट वेब को बदल रहे हैं
विषय सूची
मार्च 2026 में Cloudflare के CEO Matthew Prince ने SXSW में कहा कि 2027 तक bot traffic, human traffic से आगे निकल सकता है। इसके पीछे का logic समझना मुश्किल नहीं है: एक इंसान कुछ tabs खोलता है। लेकिन एक agent उसी काम के लिए parallel में सैकड़ों या हजारों requests भेज सकता है, sources compare कर सकता है, और actions prepare कर सकता है।
कई operators के लिए bots का मतलब अब तक मुख्य रूप से security problem था: scrapers, spam, और DDoS attacks । लेकिन browser agents और AI workflows के साथ अब एक दूसरी category उभर रही है: ऐसे bots जो कुछ तोड़ने नहीं, बल्कि पढ़ने, evaluate करने, और आपकी तरफ से act करने आते हैं।
यहीं पर WebMCP दिलचस्प हो जाता है। यह कोई finalized web standard नहीं है, बल्कि एक शुरुआती concept है कि websites और browser के भीतर मौजूद agents कैसे अधिक structured तरीके से interact कर सकते हैं।
WebMCP क्या है?
WebMCP एक शुरुआती approach है जो websites को browser के भीतर मौजूद agent के सामने explicit capabilities और context expose करने देता है। यानी agent को सिर्फ HTML देखकर guess नहीं करना पड़ता, या DOM scraping के जरिए मुश्किल से buttons और forms समझने की जरूरत नहीं पड़ती; website साफ तौर पर बता सकती है कि कौन-सी actions उपलब्ध हैं।
इसकी core idea सीधी है:
- Website सिर्फ visual interface नहीं, बल्कि structured capabilities expose करती है।
- Agent browser context के भीतर उन capabilities को ज्यादा सटीक तरीके से use कर सकता है।
- User tab के flow में बना रहता है, हर step को manually click नहीं करना पड़ता।
यहां सबसे जरूरी clarification यह है: अप्रैल 2026 तक WebMCP न तो ratified W3C standard है और न ही broadly available browser feature। यह अभी भी draft या preview stage की एक direction है, जिस पर Chrome publicly चर्चा और testing कर रहा है।
MCP और WebMCP में फर्क क्या है?
यहीं पर बहुत-सी discussions sloppy हो जाती हैं। WebMCP बस “websites के लिए MCP” नहीं है, और यह MCP का direct successor भी नहीं है।
- MCP सामान्य रूप से बताता है कि models और clients tools, data sources, और services से कैसे बात कर सकते हैं।
- WebMCP उस खास case से जुड़ा है जहां एक agent browser के भीतर किसी website के साथ interact करता है।
- इसलिए MCP और WebMCP related लेकिन अलग problems solve करते हैं।
यह distinction जरूरी है। वरना यह impression बनना आसान है कि पूरा open web बहुत जल्द किसी एक नए standard पर shift होने वाला है। हम अभी वहां नहीं पहुंचे हैं।
2027 तक bot traffic इतनी तेजी से क्यों बढ़ सकता है?
इसका मुख्य कारण Prince का बताया हुआ fan-out effect है। अगर आप आज एक laptop ढूंढ रहे हैं, तो शायद 5 से 10 pages खोलेंगे। लेकिन एक agent उसी काम को parallel work में तोड़ सकता है:
- एक साथ कई retailers को check करता है।
- Shipping time, pricing, return policy, और warranty compare करता है।
- Duplicate, ads, और irrelevant results को filter करता है।
- Raw browsing noise की जगह decision summary लौटाता है।
कितनी requests होंगी, यह task पर depend करता है। लेकिन direction साफ है: agents प्रति user queries की मात्रा बढ़ा देते हैं, क्योंकि वे parallel काम करते हैं और इंसान की तुलना में ज्यादा intermediate steps automate करते हैं।
मेरा व्यक्तिगत बदलाव: searching से delegating तक
मैं खुद इस बदलाव को अपने workflow में साफ महसूस करता हूं। पहले research का मतलब था query लिखना, तीन से दस tabs खोलना, खराब content हटाना, query refine करना, और फिर से शुरू करना। आज मैं उस काम का बड़ा हिस्सा delegate कर देता हूं।
मेरी daily routine का एक concrete example: जब मैं नए hardware, security updates, या tools में बदलाव track करता हूं, तो मैं सिर्फ one-off search नहीं करता। मेरे agents इन topics को बार-बार check करते हैं, filter करते हैं, और prioritize करते हैं। Critical चीजें सीधे phone पर push alert बनकर आती हैं। कम urgent चीजें dashboard या reading list में चली जाती हैं।
फर्क सिर्फ convenience का नहीं है। असली फर्क यह है कि इस तरह के setups लगातार traffic generate करते हैं, तब भी जब मैं actively browsing नहीं कर रहा होता। सिर्फ यही बात समझाने के लिए काफी है कि statistical level पर bot traffic, human sessions से कहीं तेजी से क्यों बढ़ सकता है।
Websites और SEO के लिए इसका क्या मतलब है?
मैं यह नहीं मानता कि classic SEO “खत्म” हो गया है। लेकिन मुझे यह काफी plausible लगता है कि SEO को एक नई layer से complement किया जाएगा। अब सिर्फ search engines का आपके content को समझना काफी नहीं है। Agents को भी content extract, compare, और अपने context में incorporate करना पड़ेगा।
इस next layer के लिए चार चीजें सबसे ज्यादा मायने रखती हैं:
- साफ structure: headings, tables, forms, और semantic HTML स्पष्ट होने चाहिए।
- Machine-readable data: Schema.org, consistent metadata, और clearly named fields, decorative marketing copy से ज्यादा useful हैं।
- Accessible flows: अगर जरूरी information या actions brittle JavaScript के पीछे छिपी हैं, तो agents बिना वजह slow हो जाते हैं।
- Latency और reliability: जो sites तेज, stable, और predictable response देती हैं, उन्हें technical advantage मिलेगा।
इस context में AEO (Agent Engine Optimization) शब्द आप और ज्यादा सुनेंगे। मैं इसे SEO का replacement नहीं मानता, बल्कि agentic systems के लिए एक additional visibility discipline मानता हूं।
Operators को अभी क्या करना चाहिए?
अगर आप आज कोई website, portal, या application चला रहे हैं, तो मैं hype से शुरू नहीं करूंगा। मैं hygiene से शुरू करूंगा:
- Structured data बढ़ाइए। देखें कि
Schema.orgकहां already sense बनाता है: articles, products, FAQs, organization data, breadcrumbs। - Important content को बिना unnecessary friction के reachable बनाइए। Price, availability, specifications, contact paths, और core functionality fragile UI tricks के पीछे नहीं छिपनी चाहिए।
- Forms और interaction flows को simplify कीजिए। Clear labels, stable buttons, predictable states, और clean HTML इंसानों और agents दोनों के लिए बेहतर हैं।
- Performance को rigorously measure कीजिए। Slow response times, unnecessary redirects, और unstable frontends visibility और usability दोनों घटाते हैं।
- Bot traffic को ठीक से अलग कीजिए। हर bot malicious नहीं होता, लेकिन हर bot valuable भी नहीं होता। Monitoring, rate limits, और clear policies ज्यादा important होंगे।
- जहां business sense बनता है, वहां structured access दीजिए। यह API, feed, clean metadata, या future में अधिक agent-friendly browser flow हो सकता है।
अगर clicks agents करेंगे, तो internet का खर्च कौन उठाएगा?
यह economic question उतना ही interesting है जितना technical question। Alphabet ने Q4 2025 में 82.3 billion dollars ad revenue report किया, जबकि Meta ने इसी period में लगभग 58.1 billion dollars report किए। ये numbers एक बात बहुत साफ करते हैं: आज का web अभी भी attention, clicks, और ad inventory पर गहराई से dependent है।
अगर users increasingly agents के जरिए answers consume करते हैं, खुद pages visit किए बिना, तो existing model पर pressure आएगा। इसका मतलब यह नहीं कि advertising अचानक गायब हो जाएगी। लेकिन इसका मतलब यह जरूर है कि direct access, data licensing, APIs, और subscription-style models ज्यादा important हो सकते हैं।
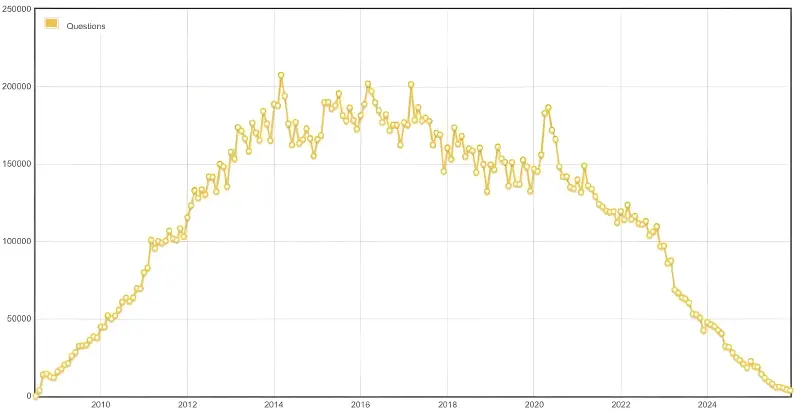
इस direction में एक interesting signal Stack Overflow से आता है। AI boom के बाद से नए questions का volume visibly pressure में है, जबकि company अपनी knowledge base और data licensing को product के रूप में ज्यादा aggressively position कर रही है। यह अभी किसी universal new model को prove नहीं करता, लेकिन direction जरूर दिखाता है: future value सिर्फ pageviews से नहीं, बल्कि licensed, structured access to knowledge से भी आ सकती है।
FAQ
क्या WebMCP अभी official web standard है?
क्या WebMCP और MCP एक ही चीज़ हैं?
क्या इसका मतलब SEO खत्म हो गया?
क्या websites को अभी तुरंत AI agents के लिए rebuild करना चाहिए?
Agents आने पर bot traffic इतना क्यों बढ़ जाता है?
निष्कर्ष
अगर आप आज कोई website चला रहे हैं, तो panic करने या कल ही सब कुछ WebMCP के इर्द-गिर्द rebuild करने की जरूरत नहीं है। लेकिन अभी से यह देखना समझदारी है कि आपका content structured, fast, machine-readable, और cleanly accessible है या नहीं।
यही चीज तय करेगी कि agentic future में आपकी site सिर्फ अच्छी दिखेगी, या वास्तव में उन systems के लिए usable होगी जो महत्वपूर्ण होंगे।
Cheers, Joe
Sources and further reading
- TechCrunch: Cloudflare CEO says online bot traffic will exceed human traffic by 2027
- Chrome for Developers: WebMCP Early Preview Program
- Chrome for Developers: When to use WebMCP and MCP
- WebMCP Draft
- Alphabet: Q4 2025 Earnings Release
- Meta: Q4 2025 Results
- Stack Overflow Data Licensing
- Prosus HY2026 Summary Consolidated Financial Statements
फिर मिलेंगे,
Joe