WebMCP explicado: agentes de IA estão mudando a web
Índice
Em março de 2026, o CEO da Cloudflare, Matthew Prince, disse na SXSW que o tráfego de bots pode superar o tráfego humano até 2027. A lógica por trás disso é simples: uma pessoa abre algumas abas. Um agente pode disparar centenas ou milhares de requisições em paralelo para a mesma tarefa, comparar fontes e preparar ações.
Para muitos operadores, bots sempre foram principalmente um problema de segurança: scrapers, spam e ataques DDoS . Com agentes de navegador e workflows com IA, surge agora uma segunda categoria: bots que não estão tentando quebrar nada, mas sim ler, avaliar e agir em seu nome.
É exatamente aí que WebMCP fica interessante. Não como um novo padrão da web já concluído, mas como um conceito ainda inicial de como sites e agentes no navegador poderiam interagir de forma mais estruturada.
O que é WebMCP?
WebMCP é uma abordagem inicial que permite que sites exponham capacidades explícitas e contexto para um agente no navegador. Em vez de obrigar um agente a adivinhar tudo a partir do HTML e interpretar botões ou formulários com DOM scraping, um site pode descrever com mais clareza quais ações estão disponíveis.
A ideia central é direta:
- Um site expõe capacidades estruturadas em vez de apenas uma interface visual.
- Um agente pode usar essas capacidades com mais precisão dentro do contexto do navegador.
- O usuário permanece no fluxo da aba, em vez de clicar manualmente em cada etapa.
O ponto importante aqui é o enquadramento: em abril de 2026, WebMCP não é um padrão ratificado pelo W3C nem um recurso amplamente disponível em navegadores. Trata-se de uma direção ainda em draft ou preview, que o Chrome está discutindo e testando publicamente.
Qual é a diferença entre MCP e WebMCP?
É aqui que muitas discussões ficam imprecisas. WebMCP não é simplesmente “MCP para sites”, nem é o sucessor direto de MCP.
- MCP descreve, de forma geral, como modelos e clientes podem conversar com ferramentas, fontes de dados e serviços.
- WebMCP trata do caso específico em que um agente interage com um site dentro do navegador.
- MCP e WebMCP, portanto, resolvem problemas relacionados, mas diferentes.
Essa distinção importa. Caso contrário, fica fácil passar a impressão de que toda a web aberta está prestes a migrar em bloco para um único novo padrão. Ainda não estamos nesse ponto.
Por que o tráfego de bots pode crescer tanto até 2027?
O ponto central é o efeito fan-out descrito por Prince. Se hoje você estiver pesquisando um notebook, talvez abra de 5 a 10 páginas. Um agente pode dividir essa mesma tarefa em trabalho paralelo:
- Ele consulta vários varejistas ao mesmo tempo.
- Compara prazo de entrega, preço, política de devolução e garantia.
- Filtra duplicatas, anúncios e resultados irrelevantes.
- Entrega um resumo de decisão em vez de ruído de navegação.
O número exato de requisições depende da tarefa. Mas a direção é clara: agentes multiplicam o volume de consultas por usuário, porque trabalham em paralelo e automatizam mais etapas intermediárias do que um ser humano.
Minha mudança pessoal: de buscar para delegar
Eu já sinto essa mudança claramente no meu próprio workflow. Antes, pesquisar significava digitar uma busca, abrir de três a dez abas, descartar conteúdo ruim, refinar a consulta e recomeçar. Hoje, eu delego boa parte desse trabalho.
Um exemplo concreto da minha rotina: quando acompanho novo hardware, alertas de segurança ou mudanças em ferramentas, eu não faço apenas buscas pontuais. Tenho agentes que revisitam esses temas, filtram e priorizam. O que é crítico chega direto ao meu celular como push. O menos urgente vai para um dashboard ou para uma reading list para depois.
A diferença não é só conveniência. A diferença real é que setups desse tipo geram tráfego continuamente, mesmo quando eu não estou navegando ativamente. Só isso já ajuda a entender por que o tráfego de bots pode crescer muito mais rápido, em termos estatísticos, do que as sessões humanas.
O que isso significa para sites e SEO?
Eu não acho que o SEO clássico esteja “morto”. Mas acho muito provável que ele venha a ser complementado. Não basta mais que os mecanismos de busca entendam seu conteúdo. Cada vez mais, agentes também precisarão extrair esse conteúdo, compará-lo e incorporá-lo ao próprio contexto.
Para essa próxima camada, quatro coisas importam mais:
- Estrutura limpa: headings, tabelas, formulários e HTML semântico precisam ser inequívocos.
- Dados legíveis por máquina: Schema.org, metadados consistentes e campos claramente nomeados ajudam mais do que marketing copy excessivamente decorado.
- Fluxos acessíveis: se informações ou ações importantes estão escondidas atrás de construções JavaScript frágeis, os agentes são desacelerados sem necessidade.
- Latência e confiabilidade: sites que respondem rápido, de forma estável e previsível, terão vantagem técnica.
Você vai ouvir o termo AEO (Agent Engine Optimization) com cada vez mais frequência nesse contexto. Eu não o trataria como substituto de SEO, e sim como uma disciplina adicional de visibilidade para sistemas agentic.
O que operadores devem fazer agora
Se hoje você opera um site, portal ou aplicação, eu não começaria pelo hype. Eu começaria pela higiene:
- Expandir dados estruturados. Revise onde
Schema.orgjá faz sentido: artigos, produtos, FAQs, organization data, breadcrumbs. - Tornar o conteúdo importante acessível sem fricção desnecessária. Preço, disponibilidade, especificações, canais de contato e funcionalidades centrais não deveriam ficar escondidos atrás de truques frágeis de UI.
- Simplificar formulários e fluxos de interação. Labels claros, botões estáveis, estados previsíveis e HTML limpo ajudam tanto pessoas quanto agentes.
- Medir performance com rigor. Tempos de resposta lentos, redirecionamentos desnecessários e frontends instáveis reduzem visibilidade e usabilidade.
- Separar corretamente o tráfego de bots. Nem todo bot é malicioso, mas nem todo bot gera valor. Monitoring, rate limits e políticas claras vão importar cada vez mais.
- Oferecer acesso estruturado onde fizer sentido de negócio. Isso pode significar uma API, um feed, metadados limpos ou, no futuro, um fluxo de navegador mais amigável para agentes.
Quem paga a internet se os agentes fizerem os cliques?
A pergunta econômica é pelo menos tão interessante quanto a técnica. A Alphabet reportou US$ 82,3 bilhões em receita de publicidade no Q4 de 2025, enquanto a Meta reportou cerca de US$ 58,1 bilhões no mesmo período. Esses números deixam uma coisa muito clara: a web atual ainda está profundamente ligada à atenção, aos cliques e ao inventário publicitário.
Se os usuários passarem a consumir respostas cada vez mais por meio de agentes em vez de visitar páginas diretamente, isso pressiona o modelo atual. Isso não significa automaticamente que a publicidade vai desaparecer. Mas sugere que acesso direto, data licensing, APIs e modelos de assinatura podem ganhar mais peso.
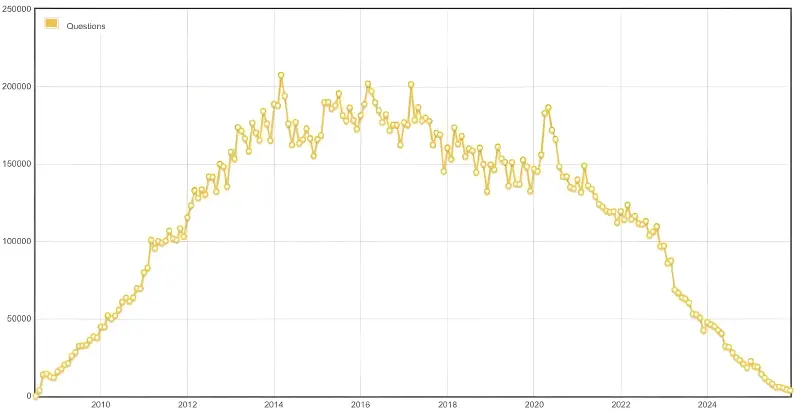
Um sinal interessante nessa direção é o Stack Overflow. O volume de novas perguntas tem estado visivelmente sob pressão desde o boom da IA, enquanto a empresa passou a posicionar de forma mais agressiva sua base de conhecimento e seu data licensing como produto. Isso ainda não prova um novo modelo universal, mas aponta uma direção: o valor pode vir cada vez mais não só de pageviews, mas também de acesso estruturado e licenciado ao conhecimento.
FAQ
WebMCP já é um padrão oficial da web?
WebMCP é a mesma coisa que MCP?
Isso significa o fim do SEO?
Os sites precisam ser reconstruídos agora para agentes de IA?
Por que o tráfego de bots aumenta tanto quando agentes entram em cena?
Conclusão
Se você opera um site hoje, não há motivo para entrar em pânico e reconstruir tudo em torno de WebMCP amanhã. Mas vale começar agora a verificar se o seu conteúdo é estruturado, rápido, legível por máquina e acessível de forma limpa.
É isso que vai determinar se, em um futuro agentic, seu site apenas parece bom ou se realmente é utilizável pelos sistemas que vão importar.
Cheers, Joe
Fontes e links úteis
- TechCrunch: Cloudflare CEO says online bot traffic will exceed human traffic by 2027
- Chrome for Developers: WebMCP Early Preview Program
- Chrome for Developers: When to use WebMCP and MCP
- WebMCP Draft
- Alphabet: Q4 2025 Earnings Release
- Meta: Q4 2025 Results
- Stack Overflow Data Licensing
- Prosus HY2026 Summary Consolidated Financial Statements
Até a próxima,
Joe