WebMCP expliqué: comment les agents IA transforment le web
Table des matières
En mars 2026, le PDG de Cloudflare, Matthew Prince, a déclaré lors de la SXSW que le trafic des bots pourrait dépasser le trafic humain d’ici 2027. La logique derrière cette affirmation est assez simple: une personne ouvre quelques onglets. Un agent, lui, peut lancer des centaines ou des milliers de requêtes en parallèle pour une seule tâche, comparer les sources et préparer des actions.
Pour beaucoup d’opérateurs, les bots relevaient surtout de la sécurité: scrapers, spam et attaques DDoS . Avec les agents de navigateur et les workflows IA, une deuxième catégorie émerge: des bots qui ne cherchent pas à casser, mais à lire, analyser et agir en votre nom.
C’est précisément là que WebMCP devient intéressant. Non pas comme un nouveau standard du web déjà finalisé, mais comme une piste encore précoce sur la manière dont les sites web et les agents dans le navigateur pourraient interagir de façon plus structurée.
Qu’est-ce que WebMCP?
WebMCP est une approche encore précoce qui permet aux sites web d’exposer des capacités explicites et du contexte à un agent dans le navigateur. Au lieu d’obliger un agent à deviner à partir du HTML et à interpréter péniblement des boutons ou des formulaires en analysant le DOM, un site peut décrire plus clairement les actions disponibles.
L’idée de base est simple:
- Un site web expose des capacités structurées au lieu de se limiter à une interface visuelle.
- Un agent peut exploiter ces capacités plus précisément dans le contexte du navigateur.
- L’utilisateur reste dans le flux de l’onglet au lieu de cliquer manuellement sur chaque étape.
La nuance importante est la suivante: en avril 2026, WebMCP n’est ni un standard W3C ratifié ni une fonctionnalité navigateur largement disponible. Il s’agit d’une direction encore au stade de brouillon ou d’aperçu, que Chrome discute et expérimente publiquement.
Quelle est la différence entre MCP et WebMCP?
C’est précisément là que beaucoup de discussions deviennent floues. WebMCP n’est pas simplement “MCP pour les sites web”, et ce n’est pas non plus le successeur direct de MCP.
- MCP décrit, de manière générale, comment des modèles et des clients peuvent dialoguer avec des outils, des sources de données et des services.
- WebMCP traite le cas spécifique où un agent interagit avec un site web dans le navigateur.
- MCP et WebMCP résolvent donc des problèmes liés, mais distincts.
Cette distinction compte. Sinon, on peut vite donner l’impression que tout le web ouvert est sur le point de basculer en bloc vers un nouveau standard unique. Nous n’en sommes pas là.
Pourquoi le trafic bot pourrait-il fortement augmenter d’ici 2027?
Le point clé, c’est l’effet de fan-out décrit par Prince. Si vous cherchez un laptop aujourd’hui, vous ouvrez peut-être 5 à 10 pages. Un agent peut décomposer cette même tâche en travail parallèle:
- Il consulte plusieurs revendeurs en même temps.
- Il compare les délais de livraison, les prix, les politiques de retour et les garanties.
- Il filtre les doublons, la pub et les résultats non pertinents.
- Il vous rend une synthèse exploitable au lieu d’un bruit de navigation.
Le nombre exact de requêtes dépend de la tâche. Mais la direction est claire: les agents multiplient le volume de requêtes par utilisateur, parce qu’ils travaillent en parallèle et automatisent plus d’étapes intermédiaires qu’un humain.
Mon basculement personnel: de la recherche à la délégation
Je ressens déjà ce basculement dans mon propre workflow. Avant, faire de la recherche voulait souvent dire taper une requête, ouvrir trois à dix onglets, jeter les contenus inutiles, reformuler la recherche, puis recommencer. Aujourd’hui, je délègue une bonne partie de ce travail.
Un exemple concret dans mon quotidien: quand je surveille du nouveau matériel, des alertes sécurité ou des changements dans des outils, je ne fais pas seulement des recherches ponctuelles. J’ai des agents qui revérifient ces sujets, les filtrent et les priorisent. Les éléments critiques arrivent immédiatement sur mon téléphone sous forme de notification. Les éléments moins urgents finissent dans un tableau de bord ou dans une liste de lecture pour plus tard.
La différence ne se limite pas au confort. La vraie différence, c’est que ce type de setup génère du trafic en continu, même quand je ne browse pas activement. Rien que cela aide déjà à comprendre pourquoi le trafic bot peut croître beaucoup plus vite, statistiquement, que les sessions humaines.
Qu’est-ce que cela signifie pour les sites web et le SEO?
Je ne pense pas que le SEO classique soit “mort”. En revanche, je pense qu’il va très probablement être complété. Il ne suffit plus que les moteurs de recherche comprennent votre contenu. De plus en plus, des agents devront eux aussi l’extraire, le comparer et l’intégrer dans leur propre contexte.
Pour cette nouvelle couche, quatre éléments comptent particulièrement:
- Une structure propre: titres, tableaux, formulaires et HTML sémantique doivent être sans ambiguïté.
- Des données lisibles par machine: Schema.org, des métadonnées cohérentes et des champs clairement nommés aident davantage qu’un discours marketing trop fleuri.
- Des parcours accessibles: si les informations ou actions importantes sont cachées derrière des constructions JavaScript fragiles, les agents sont ralentis inutilement.
- Latence et fiabilité: les sites qui répondent vite, de manière stable et prévisible, auront un avantage technique.
Le terme AEO (Agent Engine Optimization) reviendra de plus en plus souvent dans ce contexte. Je ne le vois pas comme un remplacement du SEO, mais comme une discipline de visibilité supplémentaire pour les systèmes agentiques.
Ce que les opérateurs devraient faire maintenant
Si vous exploitez aujourd’hui un site web, un portail ou une application, je ne commencerais pas par le hype. Je commencerais par l’hygiène:
- Renforcer les données structurées. Vérifiez où
Schema.orga déjà du sens: articles, produits, FAQ, données d’organisation, fils d’Ariane. - Rendre les contenus importants accessibles sans friction inutile. Les prix, la disponibilité, les spécifications, les canaux de contact et les fonctions principales ne devraient pas être cachés derrière des artifices d’interface fragiles.
- Simplifier les formulaires et les parcours d’interaction. Des labels clairs, des boutons stables, des états prévisibles et un HTML propre aident à la fois les humains et les agents.
- Mesurer les performances sérieusement. Des temps de réponse lents, des redirections inutiles et des frontends instables dégradent à la fois la visibilité et l’utilisabilité.
- Distinguer correctement le trafic des bots. Tous les bots ne sont pas malveillants, mais tous n’apportent pas de valeur non plus. Le monitoring, les limitations de débit et des politiques claires vont devenir plus importants.
- Proposer un accès structuré là où cela a du sens métier. Cela peut être une API, un feed, des métadonnées propres ou, demain, un parcours navigateur mieux adapté aux agents.
Qui paie l’internet si ce sont les agents qui cliquent?
La question économique est au moins aussi intéressante que la question technique. Alphabet a publié 82,3 milliards de dollars de revenus publicitaires au Q4 2025, tandis que Meta a annoncé environ 58,1 milliards sur la même période. Ces chiffres montrent une chose très clairement: le web actuel reste profondément dépendant de l’attention, des clics et de l’inventaire publicitaire.
Si les utilisateurs consomment de plus en plus des réponses via des agents au lieu de visiter eux-mêmes les pages, cela met le modèle actuel sous pression. Cela ne veut pas dire automatiquement que la publicité va disparaître. Mais cela suggère que l’accès direct, la licence de données, les API et les modèles par abonnement pourraient gagner en importance.
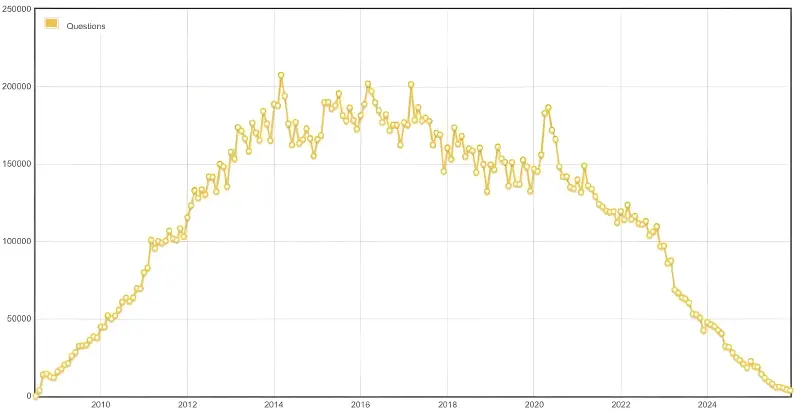
Un signal intéressant dans ce sens vient de Stack Overflow. Le volume des nouvelles questions est visiblement sous pression depuis le boom de l’IA, tandis que l’entreprise met de plus en plus en avant sa base de connaissances et sa stratégie de licence de données comme produit. Cela ne prouve pas encore un nouveau modèle universel, mais cela indique une direction: la valeur pourrait venir de plus en plus non seulement des pages vues, mais aussi d’un accès structuré et licencié au savoir.
FAQ
WebMCP est-il déjà un standard web officiel?
WebMCP est-il la même chose que MCP?
Est-ce que cela signifie la fin du SEO?
Faut-il reconstruire les sites web dès maintenant pour les agents IA?
Pourquoi le trafic bot augmente-t-il autant avec les agents?
Conclusion
Si vous exploitez un site web aujourd’hui, il n’y a aucune raison de paniquer et de tout reconstruire autour de WebMCP demain. En revanche, vous devriez commencer dès maintenant à vérifier si votre contenu est structuré, rapide, lisible par machine et proprement accessible.
C’est cela qui déterminera si, dans un futur agentique, votre site est simplement esthétique ou réellement exploitable par les systèmes qui compteront.
Cheers, Joe
Sources et liens utiles
- TechCrunch: Cloudflare CEO says online bot traffic will exceed human traffic by 2027
- Chrome for Developers: WebMCP Early Preview Program
- Chrome for Developers: When to use WebMCP and MCP
- WebMCP Draft
- Alphabet: Q4 2025 Earnings Release
- Meta: Q4 2025 Results
- Stack Overflow Data Licensing
- Prosus HY2026 Summary Consolidated Financial Statements
À la prochaine,
Joe